
Polarith AI



1.8
The pipeline of Polarith AI is divided into two major parts. First, the system needs to sample the world so that the agent is able to sense its environment, this is where AI behaviours and especially steering algorithms play a key role. Second, an agent uses these collected data and the inbuilt multi-criteria optimization to make a decision about its movement for finding the best local solution. The following figure illustrates this process, and before we go into detail for each of the two steps, let's get to know something about context steering in general.
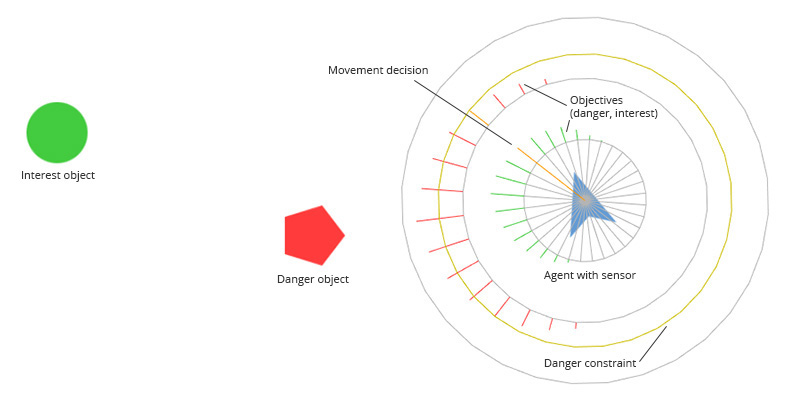
Figure 1: There are three objects: one circle at the left, one polygon at the middle and an triangular agent at the right. Around the agent, the AI mechanisms are visualized.
As you can see above, there is one object which is interesting and one object which is dangerous for our agent. From the perspective of an agent, we can classify the whole virtual world by these so called objectives. In our example, we have got two of them: interest and danger. A really interesting thing is that every decision and every action our agent can make is done with respect to these two objectives. So, for example, it wants to reach the point of interest without colliding with the dangerous obstacle, therefore, it needs to find a way to the interesting object without coming to close to the obstacle. This is achieved automatically by the way the algorithms of Polarith AI work and with the use of just one AI behaviour: "seek the objects around you", which is also known as Seek in classic steering approaches. In this example, there is no need for an active avoid behaviour or something like this. The locally best solution is found implicitly and simultaneously, for this example, it is also the best global solution. On top of this, you can precisely control how close the agent will get to the obstacle on its way to the interest object by setting a single parameter which represents how important one objective really is to an agent. Of course, there might also be more complex situations where an active avoidance will be useful (e.g. walls). Therefore, Polarith AI provides decent plug-and-play behaviours, too. This sounds fantastic, doesn't it? But how does all this work in detail? Read the next paragraphs and you will know.
The major difference of context steering compared to classic approaches is that a decision is made based on the contextual information of an agent's environment instead of weighting or prioritizing the output of the well-known classic steering (although you implicitly have this feature in Polarith AI, too). That is why the decisions made by our technology appear to be much more natural because it works more in the way humans make their decisions. When you decide about your future, you often do not simply add one possibility to another, instead you balance pros and cons to make the right decision which fits you best. That is exactly how Polarith AI works and how this balancing is applied can precisely be designed by you, the AI developer.
In the example case above, objective information is obtained by sampling the objects belonging to either interest or danger. For obtaining data for each objective, every agent has got a so called sensor which consists of receptors. Such a receptor represents a kind of feeler which is used to sample the environment based on the direction it points to, just like a tiny camera capturing a certain part of the world. In the figure above, the sensor is visualized right on top of the agent as grey circular-aligned line segments, whereby one segment represents one receptor pointing away from the agent. How this sensor is shaped for your agent is completely up to you. Note that you are not limited to such radial shapes. Currently, we support any kind of planar sensor types, e.g. line sensors which might be more useful for building racing games (we will definitely publish a decent tutorial on this). With the custom editors of Polarith AI you will be able to design your own sensor so that you control how your agent observes its world.
Now it is time to bring steering or general AI behaviours into play. The output vector of steering algorithms like Seek gets compared to every receptor direction (and optionally position) to find out how relevant a receptor, and thus, its direction is for the currently sampled object. The more a receptor points towards an interesting or dangerous object, the bigger the corresponding objective values. The results of this process can be seen in the figure below, the objectives are given by the grey circles which are located around the agent, whereby the associated colored line segments represent the magnitude of the sampled objective values. The longer a line segment, the more relevant the direction of the corresponding receptor in terms of the represented objective.
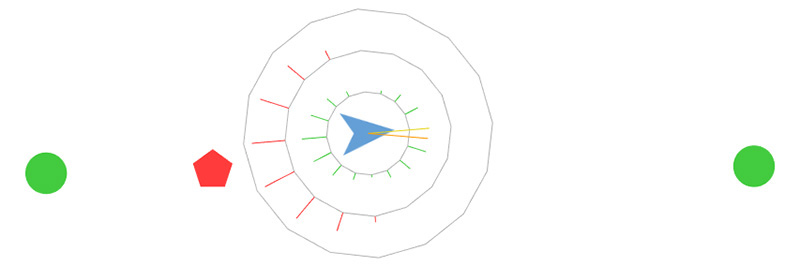
Figure 2: Our small blue agent made a very complex decision here and all it takes is a simple Seek steering. It decided to go for the right interesting object instead for the left one, although the right object is further away than the left one. Because in the context of its situation, there is also a dangerous object on its left, so it knows that it is safer to go for the right object first.
AI behaviours for writing objective values are much more powerful then their classic counterparts. The way and order how different behaviours are writing/modifying objective values influence the AI behaviour completely. One example: Seek can be set up so that the currently sampled value overwrites an existing value only if the new value is greater than the old one. In this way, Seek will act exactly like its classic counterpart. But when Seek is set up to add its response values to existing values, Seek turns into a clustering algorithm which is able to find the direction where the most objects belonging to either interest or danger are located. You can see the difference on the figure below. That said, Polarith AI gives you the same power of combinatorics like the well-known image manipulation tools out there. AI behaviours are layers and the way they are combined and blended together determines how a character acts. There is no need for higher abstraction layers to handle countless of unwanted special cases. This is the beauty of context steering and it lies in your hand.

Figure 3: Example for how powerful the layer functionality of Polarith AI really is. Here, we have two agents: the one at the top which uses Seek as clustering behaviour, and the one at the bottom which uses Seek in a classic manner. In this way, the agent at the top gets attracted stronger by multiple objects than by single objects which lie closer to it. Thus, the agent at the bottom shows exactly the opposite reaction.
So, now we have got objective values representing the world around an agent. How to make decisions based on these? For this task, you can rely on our multi-criteria optimization system of Polarith AI. You can decide what an objective stands for and the same holds true for the value magnitudes which are being accepted as solution by your agent. With the help of simple objective constraints which are also shown in the first figure of this page, you are able to create brave characters as well as very careful ones without writing a single line of code. The output of Polarith AI can easily be accessed through the corresponding components and you can use it as input or as an advice for your character controller where to move next.
At this point, you possibly might worry on how smooth the resulting movement will appear because the approach is based on a reduced discrete environment representation. Let us reassure you, therefore, our system supports AI behaviours which are processed after a decision is made. For example, Polarith AI provides a decent interpolation component which is responsible for finding better and smoother solutions lying in between receptors based on the already found solution. The following illustrates how a made decision and its corresponding interpolated version differs.
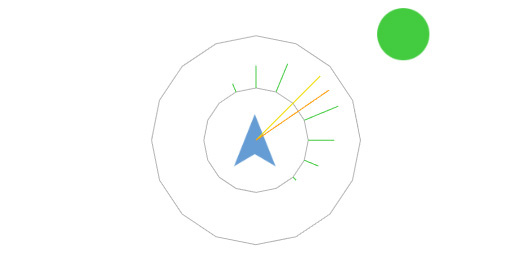
Figure 4: Illustration of the impact which the post-processing AI behaviours have on the made decision. Here, the yellow colored objective value is the best solution found, and the orange colored line indicates the interpolated solution. Hence, over time and frames, the movement of the agent appears to be smooth.